Introducing HUMANITY’S LAST EXAM (HLE)
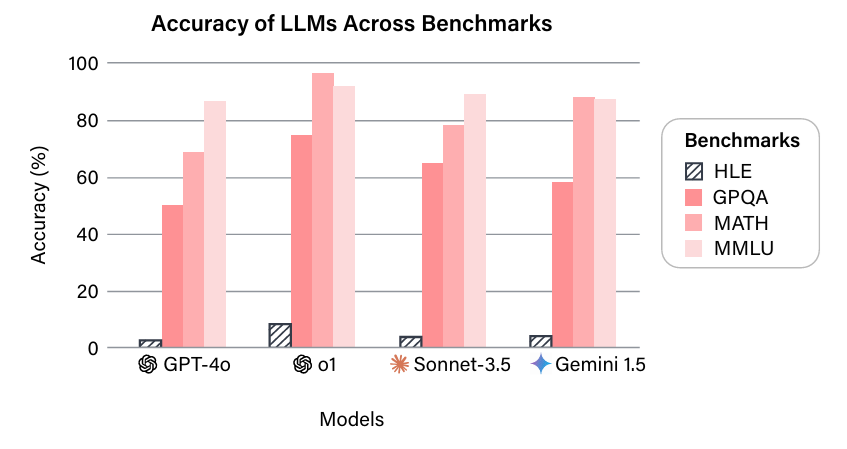
Benchmarks are essential for tracking large language model (LLM) advancements, but many, like MMLU, are saturated, with LLMs exceeding 90% accuracy, limiting their ability to measure state-of-the-art performance. To address this, HUMANITY’S LAST EXAM (HLE), a multi-modal benchmark, has been introduced as the final closed-ended academic benchmark [[1]].
HLE includes 2,500 questions across mathematics, humanities, and natural sciences, developed by global experts. Its multiple-choice and short-answer questions are designed for automated grading, with unambiguous, verifiable solutions not easily found online. Current LLMs show low accuracy and poor calibration on HLE, revealing a gap between their capabilities and expert-level human performance.
Historical trends show benchmarks are quickly saturated, with models improving from near-zero to near-perfect performance rapidly.
LLMs could plausibly surpass 50% accuracy on HLE by the end of 2025, demonstrating strong technical knowledge and reasoning.
Let’s watch how they progress in 2025.